Friday, November 29, 2019
What do you look for in a code review?
Friday, November 22, 2019
Tuesday, August 06, 2019
What is CORS?
CORS is Cross-Origin Request Security.
You can set up CORS for your site by:
- responding appropriately to
OPTIONSrequests (see theaccess-control-headers above), and - adding the
access-control-allow-originheader to your normal HTTP method responses (GET,POSTetc.) as well.
Why is CORS a thing?
In the beginning, javascript was only allowed to make requests to the same server as that bit of javascript came from. This was called the Same-Origin policy. Without the Same Origin Policy, sites would be able to make requests as each other: Mallory's website would be able to call Alice's servers, and the browser would add Alice's authentication cookie to the request.
However, that policy proved restrictive, so CORS was added to allow websites to permit requests from other origins.
How it works
- Some javascript tries to send a request to a different domain than where that javascript came from
// alice.com fetch('alice-api.com/add_user', {method: 'post'}) - The browser does the Same-Origin check and enforces the CORS policy:
- The browser sends the "preflight" request. This is an request-method=
OPTIONSrequest to the url (in this case,alice-api.com/add_user):Host: alice-api.com User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0 Access-Control-Request-Method: POST Access-Control-Request-Headers: content-type Referer: https://alice.com Origin: https://alice.com Connection: keep-alive - The different domain (in this case, alice-api.com) responds:
HTTP/2.0 200 OK date: Tue, 06 Aug 2019 02:26:03 GMT access-control-allow-origin: https://alice.com access-control-allow-headers: Authorization,Content-Type,Content-Disposition access-control-allow-methods: OPTIONS,HEAD,GET,POST,PUT,PATCH,DELETE access-control-allow-credentials: true access-control-max-age: 7200
- The browser sends the "preflight" request. This is an request-method=
- Now that CORS has been checked, the browser does the real request to the different domain: request-method=
POSTtoalice-api.com/add_user. The response generated byalice-api.commust ALSO contain the header:
or the browser will not accept it.access-control-allow-origin: https://alice.com
Wednesday, July 31, 2019
Pairing notes from session by Michelle Gleeson
Every time: Starting a session
- Can you both see the monitor? Get comfortable.
- how long will you be pairing for, when will the breaks be (every 45 minutes)
- when swap? (every ten minutes, every green test, other little goals?)
- talk through the business logic / user story
Every time: after a session:
- what was hard about the session
- what were the unexpected benefits?
- how can we make it better next time?
Key takeaway:
- most benefits realised when you combine pairing, clean code and test-driven-development.
Why pair?
- whole team accountability
- higher standards
- can go on holiday (no key-man dependency, no bus-factor, no handover)
- continuous handover
- continuous code review
- build strong team relationships (how long does this take?)
- increases inclusion and authenticity
- story about girl who hated her job until that team started pairing
- opportunities for juniors to work on critical items
- everyone learns lots of tips and tricks
- deliberate action: challenge your own thinking
- story about submarine verbalising routine possibly-dangerous actions
How to pair?
- no phones
- one monitor
- same thought process
- low level hum of quiet discussion
- if on laptop, plug in a keyboard (no hogging screen)
- mirror displays
- no slack
Quickstart to get a team used to pairing
- identify why (measurable goals, e.g. 150% improved cycle time)
- agree to a two week experiment
- work through discomfort
- be courageous
- review regularly
- what's hard
- what are the unexpected benefits
- how can we make it better
- block out time in calendar and link slack status to it so you don't get interrupted
tips and tricks:
- offsite pairing might help
- team charter to make sure values aligned
- development style: use a linter!
advanced:
- mob once a week. Several developers sitting around a shared TV, passing around the keyboard.
- use a timer to swap
- track who you pair with to make sure you get everyone. Make a chart.
- pairing cycle: make a test pass, refactor, write next (failing) test, pass over the keyboard
- everyone knows what's going on, manager can ask anyone
- team size 4-6 (bigger gets inefficient)
17 november code retreat. kata. pair with someone for 45 minutes then delete your code. dojo. new challenge for each pair.
Friday, July 26, 2019
How to avoid writing unit tests
- Use the type system -- compile errors are better than test failures
- Use libraries instead of writing your own code (and having to test it yourself as well).
- Say no to unnecessary features. Be ruthless. Every new feature means more testing.
- Test all the glue with a single integration test. Testing glue with unit tests is a waste of time:
- glue unit tests only ever fail when you're refactoring, so they are all maintenance and no protection
- they are not useful as documentation (there's no point documenting glue)
- This does NOT apply to unit tests for business logic (as opposed to glue)
- Write simpler code.
Thursday, June 27, 2019
More thoughts on Go
following The Flaws Of Go
- go is good for web servers
- garbage collector means it is not a high-performance language (Rust better here)
- `panic` is often abused as an exception mechanism
- no LLVM because it is too slow (Rust bad here)
- this means go doesn't target as many architectures
- fast compiles are a major feature. compile all your dependencies every time removes a lot of headaches:
- no more writing or learning a tool that manages dependency binaries
- no more storing dependency binaries for every architecture you might need to support
- no more binary incompatibilities
- no `const` or immutable structs is very bad, encourages poor architectural choices (Rust better here)
- simple syntax is good (Rust very bad here)
- go is good for web servers
- garbage collector means it is not a high-performance language (Rust better here)
- `panic` is often abused as an exception mechanism
- no LLVM because it is too slow (Rust bad here)
- this means go doesn't target as many architectures
- fast compiles are a major feature. compile all your dependencies every time removes a lot of headaches:
- no more writing or learning a tool that manages dependency binaries
- no more storing dependency binaries for every architecture you might need to support
- no more binary incompatibilities
- no `const` or immutable structs is very bad, encourages poor architectural choices (Rust better here)
- simple syntax is good (Rust very bad here)
Don't test the glue
Software code is basically made up of two things: business logic and glue. There are other names for it -- boilerplate, wiring -- but it is basically just code that has to be there to let the business logic do its job.
You don't want to test the glue. It is incidental code. Maintaining those tests are going to be painful and pointless.
You do want to test the business logic thoroughly. Your tests are documentation, and allow you to refactor and port to other systems.
You don't need glue tests when refactoring because refactoring is about changing the glue. Having glue tests means more work when refactoring, not less.
You don't need glue tests when documenting because the important thing about documentation is the "why" -- why the business logic does what it does, who decided it should be that way, which customer asked for it, and so on. Glue has no why, it is just incidental code. Obviously there are exceptions to this -- a complicated threading model may be the best option and should be documented and tested, for example.
You don't need glue tests when porting to other systems because they will have different glue.
Don't test the glue, except in a very small number of integration tests.
PS. "Full coverage" when doing coverage reports of which lines of code got executed in tests is not a good goal, because it means you have to test all the glue. Read a coverage report by checking that lines containing business logic are tested and ignore untested glue.
You don't want to test the glue. It is incidental code. Maintaining those tests are going to be painful and pointless.
You do want to test the business logic thoroughly. Your tests are documentation, and allow you to refactor and port to other systems.
You don't need glue tests when refactoring because refactoring is about changing the glue. Having glue tests means more work when refactoring, not less.
You don't need glue tests when documenting because the important thing about documentation is the "why" -- why the business logic does what it does, who decided it should be that way, which customer asked for it, and so on. Glue has no why, it is just incidental code. Obviously there are exceptions to this -- a complicated threading model may be the best option and should be documented and tested, for example.
You don't need glue tests when porting to other systems because they will have different glue.
Don't test the glue, except in a very small number of integration tests.
PS. "Full coverage" when doing coverage reports of which lines of code got executed in tests is not a good goal, because it means you have to test all the glue. Read a coverage report by checking that lines containing business logic are tested and ignore untested glue.
Thursday, June 06, 2019
javascript object key iteration order
I hate javascript.
Object.keys({a:true, c:true, b:true, 1:true, 3:true, 2:true})
> ["1", "2", "3", "a", "c", "b"]
Object.keys({a:true, c:true, b:true, 1:true, 3:true, 2:true})
> ["1", "2", "3", "a", "c", "b"]
Monday, June 03, 2019
Analyzing an unknown project's architecture quickly
I have been doing job interviews at work. One of the things our process involves is the "toy robot test" -- code up a solution to a problem where you need to make choices between common tradeoffs.
When analyzing the architectures to decide if I want to recommend this person to be hired as my boss, I found that the easiest way to get a quick understanding of the code was to draw what I call a "concept usage graph".
The process is as follows. I read each file, and every time a concept uses another concept, I add a link in a .dot file. Then I render the dot file and I have the graph.
So in the dotfile, we would add links from Model to Robot and Table:
Here is another example. We have a Report command. When executed, that command reads or writes from the members of a Robot.
So we add a link from the Report command to the Robot:
This way, the diagram shows all the concepts you need to understand to be able to read a particular file. It also shows all the other concepts that use whatever is defined in that file.
That way on my second pass through the source, I can work my way up the dependency tree, and always understand all the concepts required to read a file.
The graph as a whole also gives a good overview of the program. Here is my final graph:
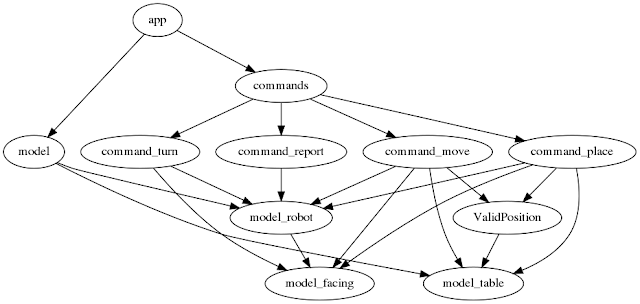
The things I don't like about this diagram (and therefore architecture) are:
- there are too many links! Perhaps there should be an abstraction for the command to use the model?
- There are links from top to almost the bottom. Perhaps app should not depend directly on model? It seems like the business logic (the commands) are not well partitioned from the domain model (model_robot and model_table)?
- there is no obvious separation between glue code and business logic
When analyzing the architectures to decide if I want to recommend this person to be hired as my boss, I found that the easiest way to get a quick understanding of the code was to draw what I call a "concept usage graph".
The process is as follows. I read each file, and every time a concept uses another concept, I add a link in a .dot file. Then I render the dot file and I have the graph.
What is a concept?
A concept can be a function, a class, a whole file, or even a module. If there is a one-to-one relationship between two things (for example, a file has exactly one method), I only mention the top-level one.How do you add a concept to your graph?
Here is an example. For the code in toyrobot (which I am actually not happy with; the point of the test is the discussion, not the code produced), there is a Model struct:
type Model struct {
*Robot
Table
}
So in the dotfile, we would add links from Model to Robot and Table:
```graphviz
digraph {
app -> { model commands }
model -> { model_robot model_table }
Here is another example. We have a Report command. When executed, that command reads or writes from the members of a Robot.
func (c Report) Execute(state *model.Model) {
r := state.Robot
if r == nil {
return
}
log.Printf("Robot at %d %d %s\n", r.PositionX, r.PositionY, r.Current.ToString())
}
So we add a link from the Report command to the Robot:
command_report -> { model_robot }
This way, the diagram shows all the concepts you need to understand to be able to read a particular file. It also shows all the other concepts that use whatever is defined in that file.
That way on my second pass through the source, I can work my way up the dependency tree, and always understand all the concepts required to read a file.
What does a typical graph look like?
The graph as a whole also gives a good overview of the program. Here is my final graph:

The things I don't like about this diagram (and therefore architecture) are:
- there are too many links! Perhaps there should be an abstraction for the command to use the model?
- There are links from top to almost the bottom. Perhaps app should not depend directly on model? It seems like the business logic (the commands) are not well partitioned from the domain model (model_robot and model_table)?
- there is no obvious separation between glue code and business logic
Wednesday, May 22, 2019
toyrobot in golang
Wrote toyrobot in golang. Thoughts:
- Golang is kind of "dumb". It has a strong emphasis on simplicity. I found myself writing very simple code. However, it is still reasonably concise.
- Not having to worry about memory management felt weird in such a low-level language. Also, since there are still pointers, the only protection from null pointer dereferences is at runtime. I had several null pointer dereference bugs during my development. Fortunately they were all found by small and simple tests, so they weren't too hard to find and fix. In a large program that would suck.
- Getting the tools running in VSCode on linux sucked. I had golang 1.10 installed somehow, but wanted to use 1.12 package features. Trying to upgrade broke my vscode -- I installed it with the snap. Setting up GOPATH and stuff wasn't fun. VSCode still doesn't work properly, doesn't highlight syntax errors or test failures.
- Writing tests was pretty straightforward.
- The effectively instant build time is definitely go's best feature.
- I suspect I would have difficulty writing efficient go code. I haven't learned the complex rules for when a struct gets copied when passed by value or when something is allocated on the heap instead of the stack. Also, garbage collection means no hard-real-time applications; GC pauses mean you can't use it for financial trading, hardware interfaces, or anything else where being a few milliseconds late is a failure. I'm having trouble thinking of other situations where that might be a problem though.
- The error checking boilerplate is pretty annoying
- I didn't use concurrency or channels, but I can see that it would be pretty useful for any kind of server app that talks/listens to other programs
- I really liked the single-binary-that-contains-everything concept. No build folder!
- I found the dependency management pretty straightforward
- Golang.org / stackoverflow was pretty good for looking up how to do things like reading from a file or parsing strings.
- Maps and slices syntax is a bit awkward
- I LOVED the everything-is-plain-old-data-with-extension-methods. I think that design decision alone strongly guides programmers toward more maintainable (less tangled) architectures.
- Packaging system very solid. My code is available almost accidentally as a library because I posted it on github. The only thing you need to do to use it is to add `import "github.com/jnnnnn/toyrobotgolang"` at the top of the source files that need it -- no `package.json` or `conanfile.py` or anything else. Exporting things that start with a capital letter is neat too.
I would recommend golang for the purpose it was designed for, server-side application-level software. Which is probably most software these days. It's not going to work for native GUIs or really high performance stuff or hardware interfaces.
Friday, May 17, 2019
Devlogs 2
I was stressed on Wednesday this week, overwhelmed with keeping track of regressions caused by a change to a React component. However, I discovered a very useful way of dealing with it -- create a whole Trello board just for the problem. Here is a screenshot of the trello board once I'd fixed all the problems.
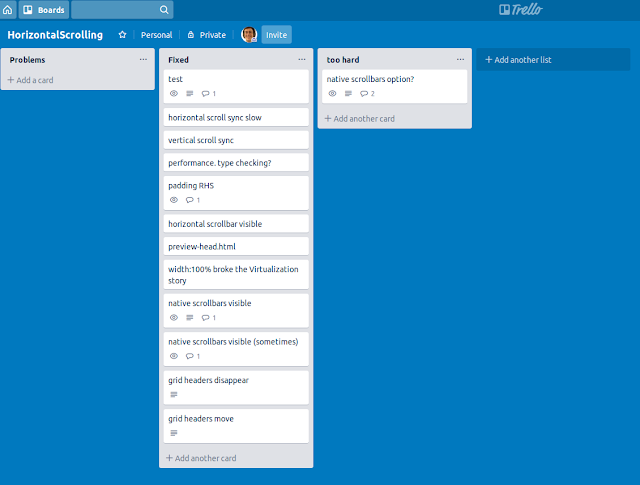
There are 11 things that gradually got added to the Problems list and got moved off it once I'd dealt with them.
I could also have written these things down on a notepad or post-its (or in my devlog) as I noticed them. Both those options would have worked pretty well too.
This also allowed me to prioritize work. Instead of having the "native scrollbars option" idea and then immediately rabbit-holing into the problem, I just added it to the list. When I came back to it, I decided that it wasn't worth doing -- although I didn't have to immediately discard the idea, keeping it around to discuss next time someone else on my team had time to talk.

There are 11 things that gradually got added to the Problems list and got moved off it once I'd dealt with them.
I could also have written these things down on a notepad or post-its (or in my devlog) as I noticed them. Both those options would have worked pretty well too.
Without Trello
I would start the refactoring, do a manual test, and notice that some things were broken. I tried to remember every problem (there were 11 separate problems in the end) and quickly got overwhelmed. I hate missing things in work so this was quite upsetting, and I found myself looking for distractions instead of focusing on the work.With Trello
When doing manual testing, whenever I noticed a problem, I just added a card to the new Problems list. And then promptly and happily ignored it and forgot about it. Once I'd finished the thing I was working on, I could come back to the Problems list to see what I needed to fix.This also allowed me to prioritize work. Instead of having the "native scrollbars option" idea and then immediately rabbit-holing into the problem, I just added it to the list. When I came back to it, I decided that it wasn't worth doing -- although I didn't have to immediately discard the idea, keeping it around to discuss next time someone else on my team had time to talk.

Monday, May 13, 2019
Large haskell program architecture
I've been doing job interviews lately and reviewing applicant's code has got me interested in quickly understanding abstractions and architectures in a novel codebase. My first step is now to draw a dependency graph -- read the code, and every time a module/function/file mentions a name, add a node for that name and an edge to the graph. This quickly builds up a picture of how the parts of the codebase are tied together. Easily-understood architectures have few edges. Bad architectures have edges from every node to every other node.
I've started applying this approach to larger programs I am considering adopting as well. For example, here is the dependency diagram for Pandoc, generated with
find pandoc/src -name '*.hs' | xargs stack exec graphmod -- -q -p | tred > graph.dot
dot graph.dot -Tsvg -ograph.svg

I've started applying this approach to larger programs I am considering adopting as well. For example, here is the dependency diagram for Pandoc, generated with
find pandoc/src -name '*.hs' | xargs stack exec graphmod -- -q -p | tred > graph.dot
dot graph.dot -Tsvg -ograph.svg

Sunday, May 12, 2019
Backpressure
Our software uses sequence-based recovery, just like TCP. Each write to the database records the sequence number, and when we start recovery we ask the other end of the connection for the next sequence number that wasn't written to the database.
However our system processes messages in several stages between several different applications. The first stage can process messages far faster than the part that writes to the database.
If there are lots of messages cued up on the other end, the database part can get overwhelmed. So if we go down for a few minutes at a busy time, we can never catch up. We try to read in too many messages, the database writes a few then crashes, and then we start again.
The standard solution to this problem is back pressure. If the database part refuses to accept too many messages, then the reader part has to wait for the database to be ready before sending more. This means that we only request messages from the other end when we have space in the queues.
Also the database part get slower if we send it too many messages at once. Its memory fills up, the processor and eventually disk caches get less efficient, and after a while it runs out of memory completely.
So back pressure actually makes the system considerably faster.
And also means it doesn't crash under load.
However our system processes messages in several stages between several different applications. The first stage can process messages far faster than the part that writes to the database.
If there are lots of messages cued up on the other end, the database part can get overwhelmed. So if we go down for a few minutes at a busy time, we can never catch up. We try to read in too many messages, the database writes a few then crashes, and then we start again.
The standard solution to this problem is back pressure. If the database part refuses to accept too many messages, then the reader part has to wait for the database to be ready before sending more. This means that we only request messages from the other end when we have space in the queues.
Also the database part get slower if we send it too many messages at once. Its memory fills up, the processor and eventually disk caches get less efficient, and after a while it runs out of memory completely.
So back pressure actually makes the system considerably faster.
And also means it doesn't crash under load.
Thursday, May 02, 2019
peak complexity

One architecture

Here is the concept usage graph of a good architecture. Note that there is a clear hierarchy.
Another architecture


Saturday, April 06, 2019
Life goals
1. Build a passion. Make a good living from it. Evaluate your personality's strengths and weaknesses, choose something you are suited to, and work at it until you love it.
2. Share an emotional connection with people who share one with you.
3. Spend time with people you respect and admire.
2. Share an emotional connection with people who share one with you.
3. Spend time with people you respect and admire.
Sunday, March 31, 2019
The meaning of life
If you're looking for the meaning of life, the answer you need is in a book called "Running on Empty" by Jonice Webb.
I spent sixteen years investigating physics and philosophy and all kinds of bullshit but it's all laid out in there.
Good luck!
I spent sixteen years investigating physics and philosophy and all kinds of bullshit but it's all laid out in there.
Good luck!
Monday, March 25, 2019
keeping a mental model of threading when writing low-level multithreaded code
You have a tree of objects in your program, e.g.

But there is also a tree of threads!

It is important to always keep BOTH mental models in your head when writing C++ code. Just like you need to track which object owns which other object (for freeing memory and avoiding memory leaks), you ened to track which thread is executing each line of code (for avoiding race conditions). This is a very common error in c++ programming, and several patterns have sprung up to avoid having to think about it. Debugging race conditions is very difficult because they are non-deterministic (they may not occur on every execution of the program, making them hard to test repeatably).
Patterns for avoiding thinking about threading in c++ include
But there is also a tree of threads!
It is important to always keep BOTH mental models in your head when writing C++ code. Just like you need to track which object owns which other object (for freeing memory and avoiding memory leaks), you ened to track which thread is executing each line of code (for avoiding race conditions). This is a very common error in c++ programming, and several patterns have sprung up to avoid having to think about it. Debugging race conditions is very difficult because they are non-deterministic (they may not occur on every execution of the program, making them hard to test repeatably).
Patterns for avoiding thinking about threading in c++ include
- a god object with locks (the worst option, not really multi-threaded)
- message passing (erlang, golang channels, "event-driven" frameworks)
- immutable objects (functional languages)