following The Flaws Of Go
- go is good for web servers
- garbage collector means it is not a high-performance language (Rust better here)
- `panic` is often abused as an exception mechanism
- no LLVM because it is too slow (Rust bad here)
- this means go doesn't target as many architectures
- fast compiles are a major feature. compile all your dependencies every time removes a lot of headaches:
- no more writing or learning a tool that manages dependency binaries
- no more storing dependency binaries for every architecture you might need to support
- no more binary incompatibilities
- no `const` or immutable structs is very bad, encourages poor architectural choices (Rust better here)
- simple syntax is good (Rust very bad here)
Thursday, June 27, 2019
Don't test the glue
Software code is basically made up of two things: business logic and glue. There are other names for it -- boilerplate, wiring -- but it is basically just code that has to be there to let the business logic do its job.
You don't want to test the glue. It is incidental code. Maintaining those tests are going to be painful and pointless.
You do want to test the business logic thoroughly. Your tests are documentation, and allow you to refactor and port to other systems.
You don't need glue tests when refactoring because refactoring is about changing the glue. Having glue tests means more work when refactoring, not less.
You don't need glue tests when documenting because the important thing about documentation is the "why" -- why the business logic does what it does, who decided it should be that way, which customer asked for it, and so on. Glue has no why, it is just incidental code. Obviously there are exceptions to this -- a complicated threading model may be the best option and should be documented and tested, for example.
You don't need glue tests when porting to other systems because they will have different glue.
Don't test the glue, except in a very small number of integration tests.
PS. "Full coverage" when doing coverage reports of which lines of code got executed in tests is not a good goal, because it means you have to test all the glue. Read a coverage report by checking that lines containing business logic are tested and ignore untested glue.
You don't want to test the glue. It is incidental code. Maintaining those tests are going to be painful and pointless.
You do want to test the business logic thoroughly. Your tests are documentation, and allow you to refactor and port to other systems.
You don't need glue tests when refactoring because refactoring is about changing the glue. Having glue tests means more work when refactoring, not less.
You don't need glue tests when documenting because the important thing about documentation is the "why" -- why the business logic does what it does, who decided it should be that way, which customer asked for it, and so on. Glue has no why, it is just incidental code. Obviously there are exceptions to this -- a complicated threading model may be the best option and should be documented and tested, for example.
You don't need glue tests when porting to other systems because they will have different glue.
Don't test the glue, except in a very small number of integration tests.
PS. "Full coverage" when doing coverage reports of which lines of code got executed in tests is not a good goal, because it means you have to test all the glue. Read a coverage report by checking that lines containing business logic are tested and ignore untested glue.
Thursday, June 06, 2019
javascript object key iteration order
I hate javascript.
Object.keys({a:true, c:true, b:true, 1:true, 3:true, 2:true})
> ["1", "2", "3", "a", "c", "b"]
Object.keys({a:true, c:true, b:true, 1:true, 3:true, 2:true})
> ["1", "2", "3", "a", "c", "b"]
Monday, June 03, 2019
Analyzing an unknown project's architecture quickly
I have been doing job interviews at work. One of the things our process involves is the "toy robot test" -- code up a solution to a problem where you need to make choices between common tradeoffs.
When analyzing the architectures to decide if I want to recommend this person to be hired as my boss, I found that the easiest way to get a quick understanding of the code was to draw what I call a "concept usage graph".
The process is as follows. I read each file, and every time a concept uses another concept, I add a link in a .dot file. Then I render the dot file and I have the graph.
So in the dotfile, we would add links from Model to Robot and Table:
Here is another example. We have a Report command. When executed, that command reads or writes from the members of a Robot.
So we add a link from the Report command to the Robot:
This way, the diagram shows all the concepts you need to understand to be able to read a particular file. It also shows all the other concepts that use whatever is defined in that file.
That way on my second pass through the source, I can work my way up the dependency tree, and always understand all the concepts required to read a file.
The graph as a whole also gives a good overview of the program. Here is my final graph:
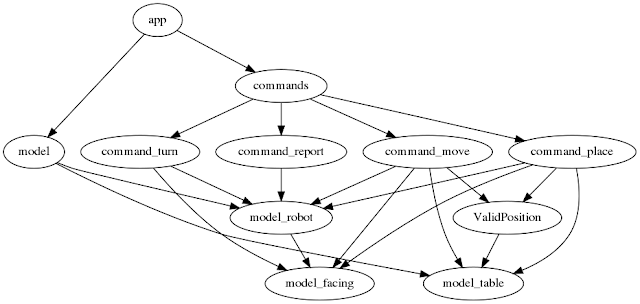
The things I don't like about this diagram (and therefore architecture) are:
- there are too many links! Perhaps there should be an abstraction for the command to use the model?
- There are links from top to almost the bottom. Perhaps app should not depend directly on model? It seems like the business logic (the commands) are not well partitioned from the domain model (model_robot and model_table)?
- there is no obvious separation between glue code and business logic
When analyzing the architectures to decide if I want to recommend this person to be hired as my boss, I found that the easiest way to get a quick understanding of the code was to draw what I call a "concept usage graph".
The process is as follows. I read each file, and every time a concept uses another concept, I add a link in a .dot file. Then I render the dot file and I have the graph.
What is a concept?
A concept can be a function, a class, a whole file, or even a module. If there is a one-to-one relationship between two things (for example, a file has exactly one method), I only mention the top-level one.How do you add a concept to your graph?
Here is an example. For the code in toyrobot (which I am actually not happy with; the point of the test is the discussion, not the code produced), there is a Model struct:
type Model struct {
*Robot
Table
}
So in the dotfile, we would add links from Model to Robot and Table:
```graphviz
digraph {
app -> { model commands }
model -> { model_robot model_table }
Here is another example. We have a Report command. When executed, that command reads or writes from the members of a Robot.
func (c Report) Execute(state *model.Model) {
r := state.Robot
if r == nil {
return
}
log.Printf("Robot at %d %d %s\n", r.PositionX, r.PositionY, r.Current.ToString())
}
So we add a link from the Report command to the Robot:
command_report -> { model_robot }
This way, the diagram shows all the concepts you need to understand to be able to read a particular file. It also shows all the other concepts that use whatever is defined in that file.
That way on my second pass through the source, I can work my way up the dependency tree, and always understand all the concepts required to read a file.
What does a typical graph look like?
The graph as a whole also gives a good overview of the program. Here is my final graph:

The things I don't like about this diagram (and therefore architecture) are:
- there are too many links! Perhaps there should be an abstraction for the command to use the model?
- There are links from top to almost the bottom. Perhaps app should not depend directly on model? It seems like the business logic (the commands) are not well partitioned from the domain model (model_robot and model_table)?
- there is no obvious separation between glue code and business logic